User : richc
Date : 17MAR2006:14:38:54
Notes:
"EM Workspace" :
Input Data Settings:
Input Data Settings:
Input Data Settings:
Model assessment plot:
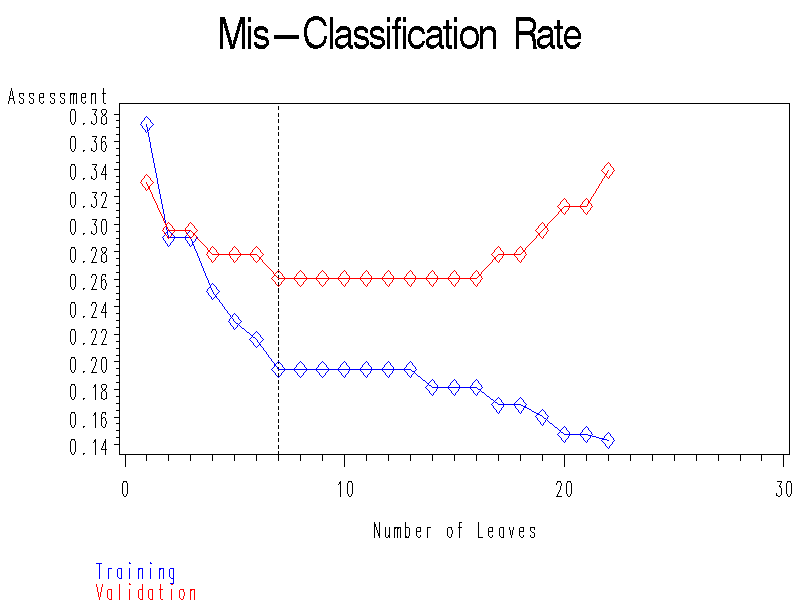
Fit Statistic Training Validation Test Average Squared Error 0.153 0.197 0.237 Sum of Squared Errors 70.661 45.419 55.070 Root Average Squared Error 0.391 0.444 0.487 Maximum Absolute Error 0.846 1.000 1.000 Divisor for ASE 462.000 230.000 232.000 Total Degrees of Freedom 231.000 . . Misclassification Rate 0.195 0.261 0.336 Number of Estimated Weights 7.000 . . Sum of Frequencies 231.000 115.000 116.000 Sum Case Weights * Frequencies 462.000 230.000 232.000
N * V N *
Node Leaf N PRIORS V N PRIORS % V 0 % V 1 % 0 % 1
26 1 37 37 28 28 64.29 35.71 81.08 18.92
38 2 16 16 4 4 25.00 75.00 25.00 75.00
39 3 5 5 2 2 100.00 0.00 100.00 0.00
15 4 5 5 2 2 50.00 50.00 0.00 100.00
9 5 13 13 4 4 25.00 75.00 15.38 84.62
5 6 110 110 61 61 80.33 19.67 82.73 17.27
3 7 45 45 14 14 35.71 64.29 28.89 71.11
Target information
Name: CHD
Label: chd
Measurement: binary
Tree settings
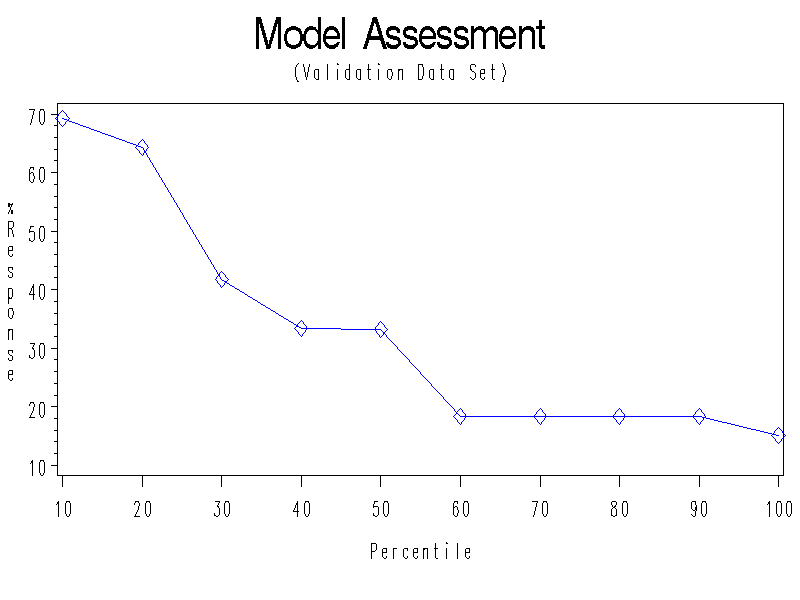
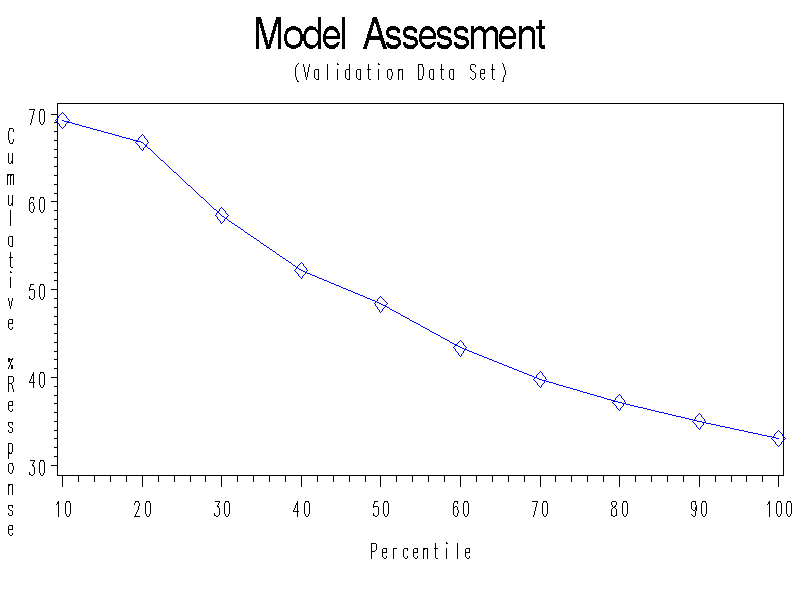
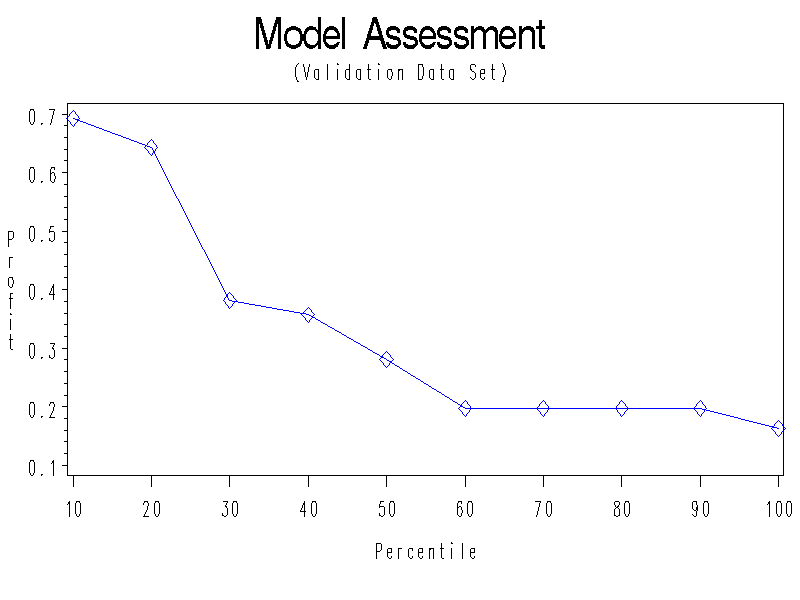
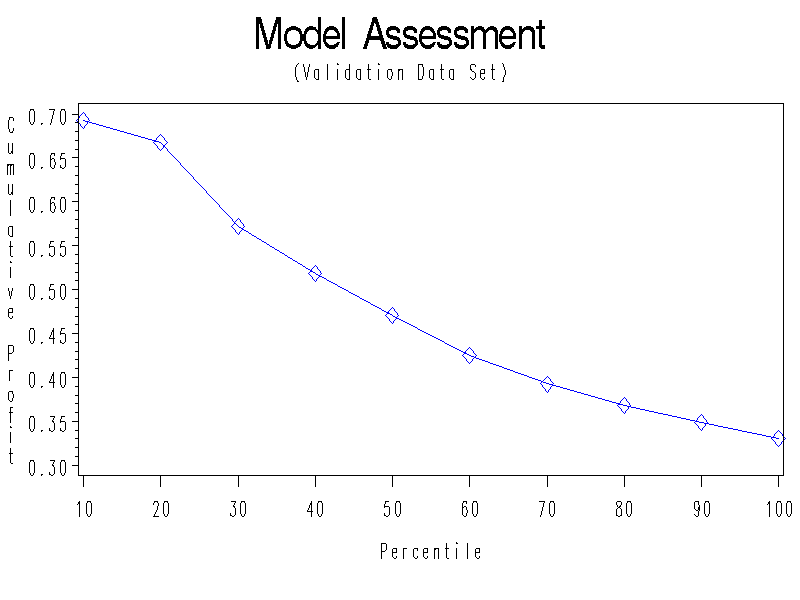
Confusion Matrix (Assessed Partition=VALIDATION)
End Report